Category: Programming
-
Error WMI provider al abrir SQL Server Configuration Manager
Al parecer el mezclar y después borrar versiones de 32 y 64 bits de…
READ MORE: Error WMI provider al abrir SQL Server Configuration ManagerBY
-
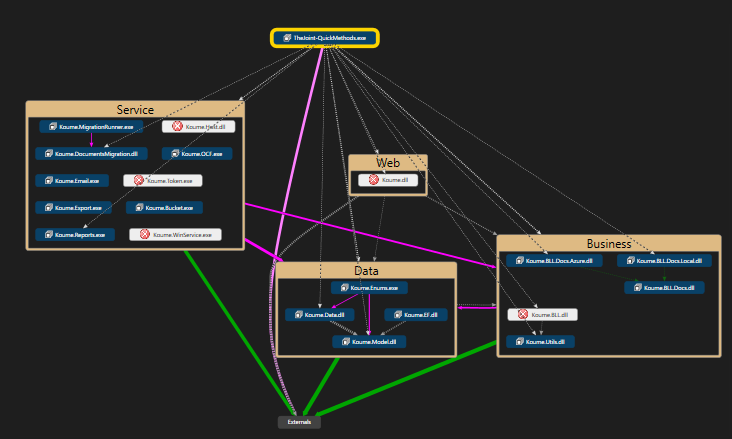
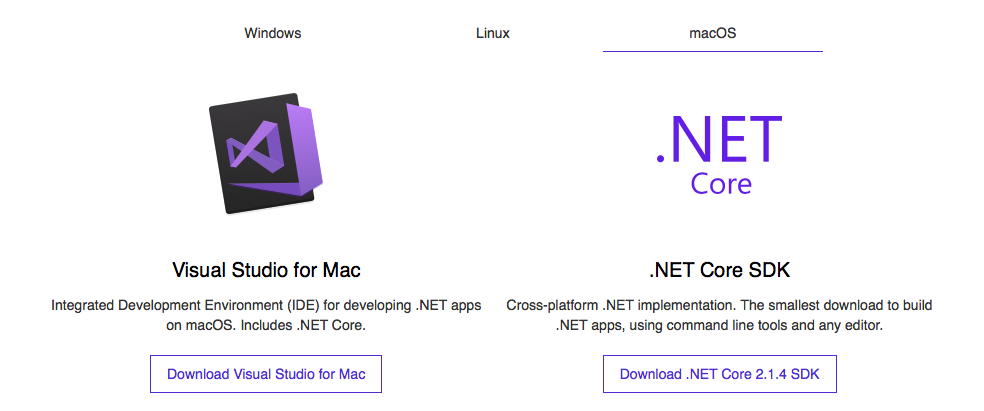
Creando un proyecto web con .NET Core en macOS
[:es]En los ultimos meses o años se ha dado un cambio interesante en las…
READ MORE: Creando un proyecto web con .NET Core en macOSBY
-
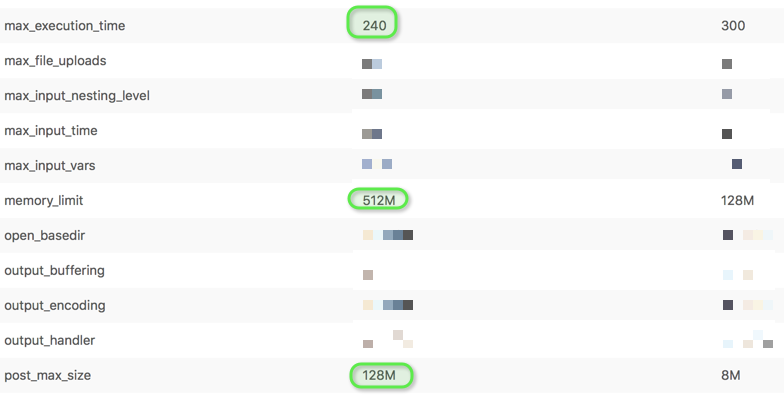
Customize PHP configuration on Azure
[:es][vc_row][vc_column][vc_column_text wrap_with_class=”no”]Una de las desventajas no ser dueño de tu infraestructura es que careces de la…
READ MORE: Customize PHP configuration on AzureBY
-
Hacer copy-paste es maligno
[:es]Hace poco, hablando con algunos de los desarrolladores de un equipo al que me tocó…
READ MORE: Hacer copy-paste es malignoBY

-
Estimaciones: La precisión construye credibilidad
[:es]Cuando hablamos del desarrollo de software, una de las cosas que al parecer resultan…
READ MORE: Estimaciones: La precisión construye credibilidadBY

-
How many nines? Understanding availability
[:es]Es muy probable que hayas experimentado un sistema caído, ya sea una aplicación en…
READ MORE: How many nines? Understanding availabilityBY

-
Determine the size of the monster first
[:es]Muchas veces he escuchado a clientes o compañeros desarrolladores decir “Vamos a usar x…
READ MORE: Determine the size of the monster firstBY

-
Creating a WCF Service for Azure Service Fabric (II)
[:es]Este post es parte de una serie acerca Service Fabric. Introducción a Service Fabric Creando un…
READ MORE: Creating a WCF Service for Azure Service Fabric (II)BY